
$300 buys 30 AI ad variants on a wired stack and 1 hand-shot UGC ad on a traditional one. Same dollar, 30x the iteration room. The reason this matters is not the cost saving — it is that variant testing is the only reliable way to find the angle, hook, and visual that actually convert, and the algorithms on Meta and TikTok reward the volume directly. A typical ad account ships 4–6 fresh creatives per month manually. A wired engine ships 60–100. The spread between those two numbers is where most paid-acquisition results in 2026 are decided.
This is the deepest piece in our AI Creative cluster — eight stages, with the tools, cost ranges, and failure modes for each. The numbers below come from active client billing across DTC, B2B SaaS, and agency accounts in mid-April 2026, plus what we run for digicore101 itself. We will be specific about prices and tool names; vague about exact prompts and per-client review checklists for reasons readers in this corner of the industry already understand.
What an ad creative engine actually is
An ad creative engine is a pipeline that turns a small set of inputs (brand, product, audience, competitor library) into a continuous stream of testable ad variants — usually 30–100 per launch, refreshed weekly. The engine has eight stages. Stages 0–4 produce the variants. Stages 5–7 ship them, measure them, and feed the winners back into the upstream stages.
What the engine is not: a single tool that takes a product link and outputs an ad. Those exist (Creatify, Canva Grow, AdCreative.ai), and they are useful for the smallest stage of the pipeline, but if a tool that costs $50 a month replaced a media buying team, paid acquisition would be a solved problem. It is not. The engine wraps those tools inside the upstream creative work the tools do not do.
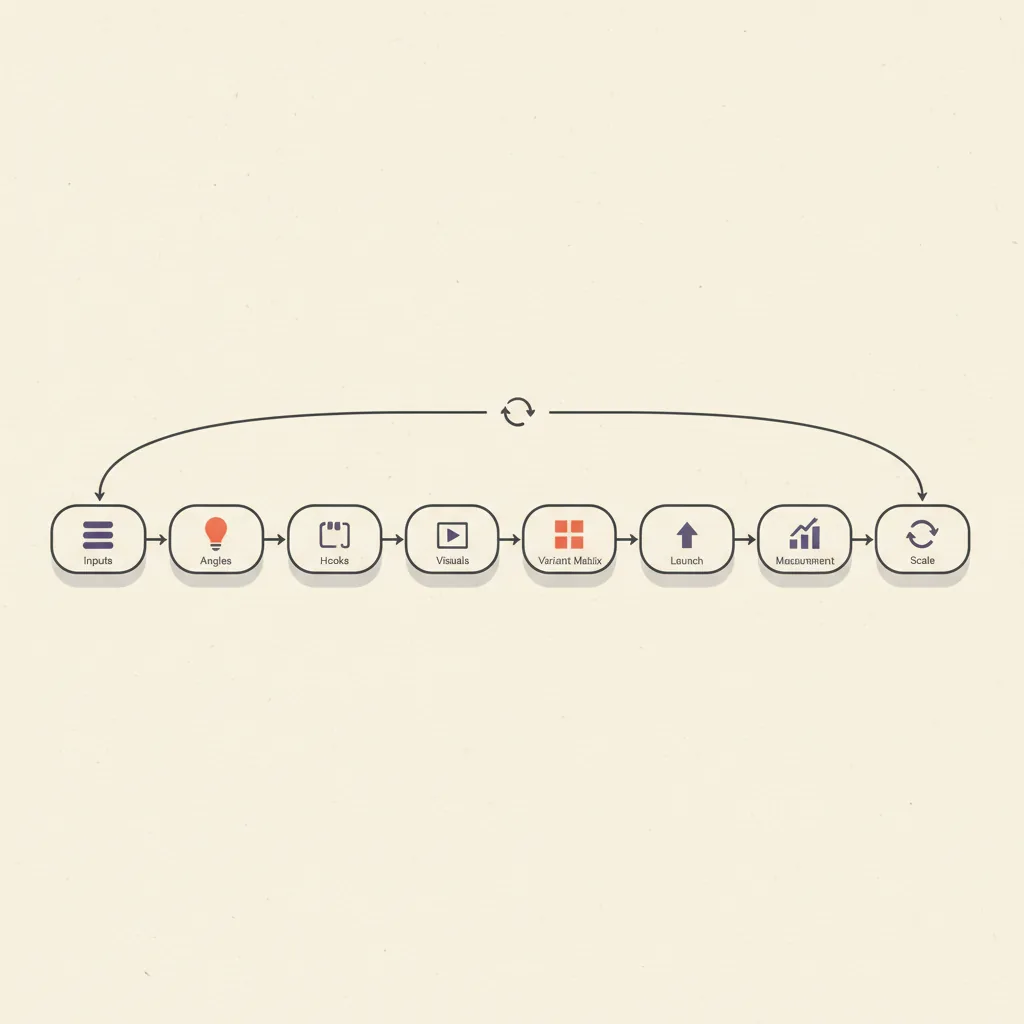
Stage 0 — Inputs
Everything downstream is shaped by what you feed in at stage 0. Skipping this stage is the single most common reason engines produce ads that look generic — the model has nothing specific to grip on, so it outputs the average of the internet.
Four input artifacts feed every stage:
- Brand voice — 10–20 reference assets (existing ads, product pages, founder posts, support replies) plus a one-page voice profile (tone, banned phrases, trademark vocabulary). We use the brand-voice skill to derive this from real source material rather than asking the founder to describe it abstractly.
- Product knowledge — what it is, what it costs, what problem it solves, what it replaces, the three to five proof points (numbers, testimonials, before/after). The brief shape we use is one page, structured.
- Audience research — who the buyer is, what they were doing before this product, what they searched, what they fear, what language they use. Sources: support tickets, sales-call transcripts, Reddit threads in the buyer's subreddit, app store reviews, post-purchase survey free-text.
- Competitor creative library — 50–200 active competitor ads scraped from Meta Ad Library and TikTok Creative Center. Tag each by angle, hook style, visual format. This is the cheapest market research most teams skip.
Why this matters: an angle generator with thin inputs produces 20 variations of "save time and money". An angle generator with 200 tagged competitor ads, real customer language, and a product brief produces 20 distinct angles each with a specific buyer in mind.
| Input | Source | Tool | Time to assemble |
|---|---|---|---|
| Brand voice profile | Existing assets, founder writing, support replies | Claude or GPT + manual edit; brand-voice skill if you have one | 4–6 hours, once per brand |
| Product brief | Founder interview, product page, pricing page | Markdown template populated by hand | 2–3 hours, once per product |
| Audience research | Support tickets, sales calls, Reddit, reviews | Tavily or Exa for Reddit; Gong / Fathom for sales calls | 6–10 hours, refresh quarterly |
| Competitor creative library | Meta Ad Library, TikTok Creative Center | Apify scraper or manual download; tag in Notion or Airtable | 8–12 hours initial; 1 hour weekly refresh |
Stage 1 — Angle generation
An angle is the underlying claim the ad makes about the product — the reason this person, today, should care. "Faster than the alternative" is an angle. "Costs less than your monthly latte habit" is a different angle. "Used by [recognizable peer]" is a third. Most teams ship one angle across all their creative and wonder why CAC stops dropping; the engine ships 10–20 angles per product per launch.
The brief shape we use, kept abstract because the prompt itself is a working asset:
- Read the four input artifacts (brand voice, product brief, audience research, competitor library).
- Cluster competitor ads by angle. Identify which angles are saturated and which are under-shipped.
- Generate angles in three buckets: pain-driven, aspiration-driven, social-proof-driven. Aim for 4–8 in each bucket, then cull to the strongest 10–20.
- Each angle has a one-line statement, the buyer it targets, and the proof point it leans on.
We run this on Claude API (Sonnet 4.6 for the cluster, Opus when the brand voice is unusual). Cost: $0.10–$0.40 per angle batch. The output goes into an Airtable angle bank that the team reviews and tags before any of it touches the visual stages. Most angle output is mediocre on first generation — the value is in the second pass where a human editor kills the bottom 50% and rewrites the top 20% to sharpen the buyer specificity.
Stage 2 — Hook + script generation
A hook is the first 1–3 seconds of the ad. On TikTok and Reels, 70% of viewers bounce inside that window if the hook is weak; the rest of the ad never gets seen. We generate 4–6 hook variations per angle, length-banded to the platform format (6s for TikTok bumpers, 15s for stories, 30s for Reels and feed).
Hook patterns we generate against, by performance tier observed in client accounts:
| Pattern | Format | Where it fits | Notes |
|---|---|---|---|
| Pattern interrupt | Visual gag, unexpected object, hard cut | TikTok, Reels, YouTube Shorts | Highest hook rate; lowest brand recall |
| Direct question | "Anyone else tired of [pain]?" | Meta feed, Stories | Reliable performer; can read as templated if overused |
| Bold claim | "This replaces [tool] for $9/mo" | Meta feed, X, LinkedIn paid | Works when the claim is provable; tanks when it is not |
| Social proof | "[Number] people switched in [time]" | Meta feed, Reels | Best with a real number; disclosure rules apply |
| Reframe | "Most [audience] do this wrong" | TikTok, LinkedIn paid | Native to TikTok rhythm; reads as bait on Meta feed |
| Founder-led | Talking head, "I built this because…" | Meta feed, LinkedIn paid | Strong CVR; weak CTR; needs paired metrics |
The script that follows the hook is shorter than most teams expect. For a 15s ad, we plan a 3-second hook, a 6-second proof, a 4-second CTA, and 2 seconds of brand close. Length-banding is enforced at generation time — the LLM is given an explicit token cap per scene, not asked nicely to be brief. Cost per hook batch: $0.05–$0.15 on Claude or GPT.
Stage 3 — Visual asset generation
Visuals split into three tracks, run in parallel: static images, video B-roll, and UGC-style avatar shots. The right model depends on the format and the role of the asset in the spot. We covered the model-by-model comparison in detail in two cluster siblings — see AI image generators compared and best AI video ad tools. The summary table below is the routing rule we apply at this stage.
| Asset type | Primary model | Fallback | Cost per asset |
|---|---|---|---|
| Static product image, photoreal | Nano Banana (Gemini 2.5 Flash Image) | Flux Pro 1.1 | $0.04–$0.08 |
| Static product image, illustrated | Flux Pro 1.1 | Ideogram 2 | $0.05–$0.10 |
| Brand pattern / abstract | Midjourney v7 | Flux Schnell | $0.10–$0.30 |
| Video B-roll, 5–10s clips | Seedance Pro | Kling 2.0 | $0.10–$0.30 per clip |
| Video hero shot, 5s premium | Sora 2 | Veo 3 | $1.00–$1.50 per clip |
| UGC avatar, talking head | Arcads | Creatify, MakeUGC | $2–$5 per spot, monthly seat |
| Voiceover, synthetic | ElevenLabs | PlayHT | $0.02–$0.10 per spot |
The decision rule we use at this stage: use the cheapest model that survives editorial review. Sora produces the prettiest 5 seconds of footage on the market in April 2026, and it is also 4–10x more expensive than Seedance. For 80% of B-roll the difference is invisible inside a 15-second cut with motion graphics over the top. We route Sora and Veo to hero shots only, where the frame sits on screen long enough for the quality difference to matter.
UGC-style avatars are the largest line item in this stage for any brand running creator-style spots. What is AI UGC covers the format in depth. The shortcut: Arcads for a curated avatar library and clean output; Creatify when you also need the assembly layer; MakeUGC when the budget is tight and the editor will fix the rough edges. AI vs real UGC covers when to actually pay a human creator instead.
Stage 4 — Assembly + variant matrix
Stage 4 is where the engine stops being a content factory and starts being a testing system. The matrix is a table of every angle multiplied by every hook variant multiplied by every visual treatment multiplied by every CTA. Six angles times four hooks times three visual treatments times two CTAs is 144 theoretical variants — we cull to the 30–60 that survive editorial review.

Assembly itself is the cheapest stage if you have committed to the right tooling. Three approaches we run depending on team shape:
- CapCut + templates — fastest for a small team. Build 3–5 master templates per format (15s product spot, 30s explainer, 6s bumper). Drop new visuals and hooks into the template. ~10 minutes per finished variant once the template is dialed.
- Creatify or Arcads — assembly-included tools. Best when the avatar plus B-roll plus captions all live in the same product. Lock you in but cut the editor step.
- Premiere or Final Cut — for hero spots only. The expense is editor hours, not software; if you are paying $80/hr for a finished variant that the algorithm will kill in 7 days, you are over-investing in production.
The matrix lives in Airtable or a spreadsheet — every variant has a row with its angle ID, hook ID, visual ID, CTA ID, format, and target placement. This is the artifact stage 6 (measurement) reads when it ranks performance.
Stage 5 — Launch + budget allocation
Launch is where the engine meets Meta and TikTok. The campaign structure decides whether your variant testing actually finds winners or just spreads spend thin across noise.
Three structural choices we make at launch:
- CBO over ABO for variant testing — Campaign Budget Optimization lets Meta's algorithm reallocate budget across ad sets toward the better performers. With 30+ variants, manual reallocation across ABO ad sets is wasted human time.
- Dynamic Creative Optimization (DCO) for production — once a variant cluster has won, DCO mixes the winning components (hook A + visual B + CTA C) automatically. This is where AI-generated variant volume actually pays off; DCO needs the spread.
- Honor the 7-day learning rule — Meta needs ~50 conversions per ad set per week to exit learning. If your spend or your variant count cannot support that, consolidate ad sets. Splitting $30/day across 12 ad sets keeps every one of them in learning forever.
Budget shapes for variant testing we apply on Meta: $50–$100/day per ad set, 3–5 ad sets per campaign, 6–10 variants per ad set on rotate. Total daily spend in the $200–$500 band is the sweet spot for finding signal in a 14-day test window. Less than that is too noisy; more than that is over-investing before the winners are clear. our facebook ads service page covers the full media buying workflow we layer on top of the creative engine.
Stage 6 — Measurement + winner selection
The metrics that matter at this stage are not the ones the platform foregrounds. CTR is loud and mostly a hook-rate proxy; CVR is quieter and more honest. The full kit:
| Metric | What it tells you | Signal or noise |
|---|---|---|
| Hook rate (3-sec view rate) | How well the first 3 seconds hold | Signal — direct hook quality |
| Hold rate (15-sec / 25%) | Whether the script keeps watching | Signal — angle quality |
| CTR (link click-through) | Headline + CTA pull | Mixed — confounded by audience |
| CVR (post-click conversion) | Whether the click was qualified | Signal — final winner test |
| CAC by variant | True acquisition cost | Signal — what to scale |
| ROAS (over 7+ days) | Revenue payback | Signal at scale; noisy at low spend |
| Engagement (likes, comments) | Social signal | Mostly noise for paid |
| Reach / impressions | Distribution volume | Volume metric, not quality |
Winner selection rule we use: a variant earns scale if it beats the account average on hook rate by 1.3x AND CAC is at or below target for 7 consecutive days at $100+/day spend. Most variants that look like winners on day 2 regress to mean by day 7. We do not promote anything below that bar; promoting too early is how teams burn budget chasing false positives.
The boring infrastructure: variant IDs in the ad name, performance pulled into a spreadsheet via Meta Ads API or a tool like Triple Whale, weekly review session where the team kills the bottom third, scales the top 10–20%, and feeds the rest back into stage 1 (with notes on why they died).
Stage 7 — Scale + iterate
A winning variant has a half-life. Most spend out within 14–28 days as audience saturation rises and creative fatigue degrades CTR. Scale at this stage is two parallel jobs: scale spend on the winner while you have it, and feed what worked back into the upstream stages so the next batch starts smarter.
Three moves at this stage:
- Scale the winner with budget, not duplication — increase spend on the winning ad set 20–30% every 3 days while CAC holds. Do not duplicate ad sets to scale; that fragments learning and the duplicated copy almost always underperforms the original.
- Refresh visuals on the winning angle — the angle stays; the hook and visual rotate. A winning angle plus three new hooks and visuals usually outperforms the original variant by week three because fatigue resets even when the underlying claim does not.
- Promote winners to real UGC — once an AI-shot variant has cleared $5k in spend with positive ROAS, commission the same script with a real human creator. The creator-shot version often performs 1.5–2x the AI-shot version on conversion (not CTR), which is when real UGC earns its higher production cost. The full when-to-use-which decision is in AI vs real UGC.
Cheap stack vs expensive stack
The variant volume comparison most teams care about: how many fresh creatives the engine actually ships per week against a manual baseline.
The cost picture by team size and budget:
| Team / budget | Stack | Tooling cost / mo | Variants / week |
|---|---|---|---|
| Solo founder, < $5k/mo ad spend | Cheap | $300–$500 | 15–25 |
| Small team, $5–25k/mo ad spend | Mid | $700–$1,500 | 40–70 |
| Brand team or agency, $25k+/mo ad spend | Wired | $2,000–$5,000 | 80–150 |
| Manual baseline (no engine) | Hand-shot UGC + Canva | $1,500–$4,000 in creator fees | 4–6 |
What the cheap stack looks like in April 2026: Claude API or GPT for angles and hooks ($30–$80/mo), Nano Banana and Flux for static images (~$50/mo), Seedance for video B-roll (~$100/mo), Arcads or MakeUGC for one avatar seat ($100–$200/mo), CapCut for assembly (free or $10/mo), Meta Ad Library scraper ($30/mo for an Apify actor). Total around $300–$500/mo plus ad spend. Output: 15–25 testable variants a week from a solo operator.
The expensive stack adds Sora or Veo for hero shots, Midjourney for brand pattern work, an all-in-one assembly platform like Creatify Pro, and possibly a media buying agency layer on top. Output is roughly 2–3x the cheap stack but the cost is 6–10x. The ratio rarely favors the expensive stack until ad spend clears $50k/month.
Common failure modes
Patterns we see in audits of broken ad creative engines:
- Skipping stage 1 (angles) — going straight from product brief to visual generation. The engine ships 60 variants of one angle. Volume without angle diversity does not give the algorithm anything to choose between.
- Over-investing in stage 3 (visuals) — paying $1.20 per second of Sora for everything when 80% of the cuts could be Seedance at $0.10. The expensive video model rarely changes the winner; the angle does.
- Ignoring the brand voice profile — letting the LLM default to its house style. The output reads as competent and forgettable. Buyers can tell when copy was written for them vs about them.
- Variant volume without measurement infrastructure — shipping 60 variants a week with no naming convention, no spreadsheet, no weekly review session. The engine is producing data the team cannot read.
- Promoting too early on too little spend — declaring a winner at day 2 with $30 of spend behind it. Every "winner" picked at that bar regresses by day 7. Wait for the full week and the $100+/day spend bar before promoting.
- Killing winners by duplicating ad sets — Meta's algorithm penalizes duplicated creative; the duplicate cannibalizes the original instead of scaling it. Increase spend on the original ad set; do not clone.
- Treating the engine as one-and-done — wiring the stack, shipping one batch, walking away. Every engine needs a weekly review session and a quarterly refresh of the input artifacts (especially the competitor library).
How this fits the rest of our stack
This is the visual content engine. The text content engine is its sibling — same architecture, different output unit, different humanizer rules. The full architecture spans both: how to build an AI content engine covers the five engines (SEO, social, email, video, ads), and this post is the deep build of the ads engine specifically.
Inside the AI Creative cluster, the supporting reads are:
- What is AI UGC — the synthetic creator format that powers stage 3 avatar work.
- AI image generators compared — Nano Banana, Midjourney, Flux, Ideogram for static creative at stage 3.
- Best AI video ad tools — Arcads, Creatify, MakeUGC for production-volume survival.
- AI vs real UGC — when to scale the AI variant to a real human creator at stage 7.
We build these engines for clients as part of our AI Creative service. The typical engagement is 6–8 weeks to wire stages 0–4 with the client's inputs, plus 4–6 weeks of editorial calibration before the engine is producing winners reliably. If you would rather have us audit the existing creative process before committing to a build, see AI Stack Audit.
Where this is heading
Three shifts worth tracking through the back half of 2026:
- Variant volume keeps rising as the bar. Meta and TikTok are openly building product around the assumption that advertisers will ship 50–100 variants per launch. Accounts that cannot match that volume will lose distribution share to accounts that can.
- AI-generated UGC will hit a quality plateau before it hits parity with real creators. The gap on talking-head emotion and product handling is real and will close slowly. The hybrid play — AI for angle and hook discovery, real creators for the winners — is where the next 18 months of ROAS lives.
- Platform-side creative scoring is converging with creator-side variant generation. Meta's Advantage+ and TikTok's Smart Performance Campaign already optimize creative selection in-platform; the engines that win will be the ones whose upstream stages (angle, hook, brand voice) feed enough variant diversity to give the platform real signal to rank against.
The teams that win paid acquisition over the next two years are the ones running this engine end-to-end, with the inputs refreshed monthly and the variant matrix reviewed weekly. The tools are the cheapest part. The discipline is the expensive part — and the discipline is what most accounts will not have.